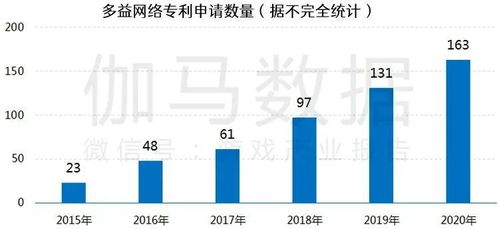
从传统数据中心向以人工智能为核心的智算中心演进,不仅是硬件算力的堆砌,更是一场深刻的网络技术变革。要打通这一转型路径,网络技术的研发需在以下几个关键环节实现突破与协同。
一、 互联架构:从通用到异构,拥抱超大规模无损网络
传统数据中心网络基于TCP/IP协议栈,为通用计算设计,存在延迟、丢包和拥塞等问题。而智算中心的核心——大规模AI集群训练(如万卡集群)对网络提出了近乎严苛的要求:超高带宽、超低延迟、零丢包。因此,技术研发必须聚焦:
- RDMA(远程直接内存访问)技术的深度应用与优化:绕过操作系统内核,实现服务器间内存的直接、高速访问,是降低延迟的关键。需要解决RDMA大规模部署下的流量控制、拥塞管理、与现有基础设施融合等问题。
- 新型互联协议与交换架构:如InfiniBand,凭借其原生无损特性和低延迟,已成为高端智算网络的主流选择。基于以太网的RoCE(RDMA over Converged Ethernet)技术也在快速发展,旨在将以太网的生态优势与RDMA的高性能结合,其核心在于通过PFC(优先级流控制)、ECN(显式拥塞通知) 等机制实现“无损以太网”。研发重点在于提升RoCE的规模化部署能力和稳定性。
- 非阻塞网络拓扑:采用Clos、Dragonfly+ 等拓扑结构,构建无阻塞、高带宽、多路径的网络平面,以满足成千上万个加速卡(GPU/ASIC)间全连接通信的需求。
二、 计算与网络的协同设计:解耦与重构
智算中心中,计算(GPU/NPU)与网络的关系从“连接”变为“融合”。技术环节包括:
- 片间互联与节点内互联:在单个服务器节点内部,多颗加速卡之间通过NVLink、PCIe 等高速互联技术形成紧密耦合的计算单元。网络技术需与这些内部互联协议高效对接,形成统一的内存地址空间和通信域。
- 网算一体与智能网卡(DPU/SmartNIC):将部分网络、存储和安全功能从CPU卸载到专用的数据处理单元(DPU)或智能网卡上。这不仅能解放CPU资源,更能实现网络协议的在网处理、集合通信优化(如All-Reduce操作的部分卸载),从而大幅提升整体系统效率。这是研发的前沿热点。
三、 网络智能化与可观测性:从被动运维到主动调度
智算工作负载(尤其是分布式训练)动态多变,网络必须更加智能。
- AI赋能的网络自治:利用机器学习模型预测流量模式、实时检测与规避拥塞、自动优化路由策略,实现网络的自配置、自修复、自优化。
- 端到端的精细化可观测性:部署细粒度的遥测技术(如INT,带内网络遥测),实时采集网络路径上的延迟、丢包、队列深度等数据,并结合训练作业的语义信息(如迭代周期),快速定位性能瓶颈是在计算、存储还是网络,实现跨层调优。
四、 光互联技术:突破带宽与距离的物理极限
随着单芯片速率向800G、1.6T发展,电互联在功耗和距离上的瓶颈日益凸显。光互联 技术成为必然选择:
- CPO(共封装光学)和NPO(近封装光学):将光引擎与交换芯片或计算芯片封装得更近,极大降低接口功耗和尺寸,是未来超高速互联的核心方向。
- 高速光模块与硅光技术:研发更低功耗、更低成本的800G/1.6T高速光模块,利用硅光技术实现光电集成的大规模生产。
五、 软件定义与自动化:统一编排的基石
硬件变革需要软件定义来驱动。
- 统一通信库与编排:优化NCCL、OneCCL 等集合通信库,使其能充分感知底层异构网络(IB、RoCE)的拓扑和特性,实现最优通信算法选择。
- 云网智一体化的资源调度:通过软件定义网络(SDN)和智能编排器,将网络资源(带宽、拓扑)与计算资源(GPU)、存储资源作为一个整体进行统一调度和弹性分配,根据AI任务的需求动态生成最优资源组合。
而言,从数据中心到智算中心的网络技术打通,是一条从“通用互联”走向“智算融合” 的路径。它要求研发不再局限于单纯的带宽提升,而是需要围绕无损传输、异构协同、网算一体、智能运维和光电融合等多个维度进行系统性的创新与整合。只有打通这些环节,网络才能从“管道”进化为智能计算的“神经系统”,真正支撑起智算时代的万千应用。